CyVerse UK (previously known as iPlant) was born as a collaborative effort between
CyVerse and a small number of UK universities and institutions to build on the
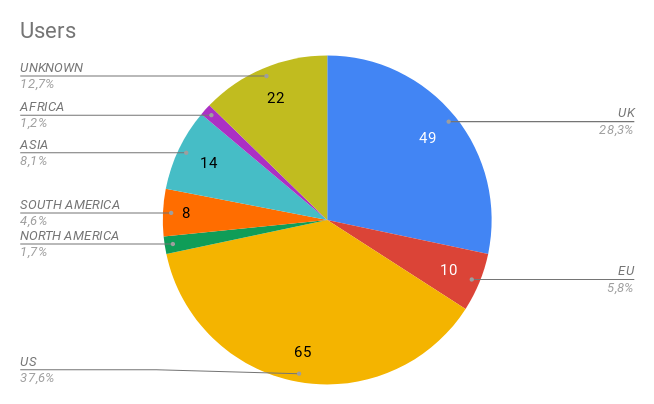
CyVerse experience and provide the same services to UK users. UK users have a geographical advantage in using UK based resources and can benefit from a UK based assistance.
CyVerse UK is not only benefiting UK researchers, but the whole life science community, with jobs submitted from almost every continent.
With hardware and staff hosted at the Earlham Institute, users benefit from application developed at EI often being integrated in the platform.